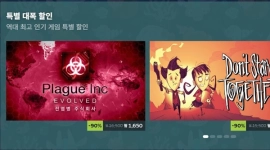
한국게임학회 문화예술분과, 명지전문대학, OGQ는 지난 1월 23일 공동으로 서울 광화문 한국콘텐츠진흥원에서 '인공지능 시대, 문화데이터 공유체계의 개념과 쟁점' 세미나를 개최했다. 이번 세미나는 생성형 AI 확산에 따라 중요성이 부각된 AI 학습용 문화데이터의 구축, 공유, 책임 구조를 논의하기 위해 마련됐다. 참석자들은 공공 데이터 정책, 유럽의 문화데이터 거버넌스 사례, AI 윤리 및 편향 문제 등 다각적인 주제를 다뤘다
▲ 한국게임학회 로고 (사진제공: 한국게임학회)
한국게임학회 문화예술분과, 명지전문대학, OGQ는 지난 1월 23일 서울 광화문 한국콘텐츠진흥원에서 '인공지능 시대, 문화데이터 공유체계의 개념과 쟁점' 세미나를 개최했다.
이번 세미나는 생성형 AI 확산에 후 중요성이 부각된 AI 학습용 문화 데이터 구축, 공유, 책임 구조를 주제로, 공공 데이터 정책, 유럽의 문화 데이터 거버넌스 사례, AI 윤리와 편향 문제를 논의하는 자리로 마련됐다.
이권수 한국문화정보원 문화빅데이터팀장은 '한국형 소버린 AI 추진을 위한 문화데이터 전략적 구축 방안'을 주제로 발표했다. 이 팀장은 “현재의 AI는 한국어를 처리할 수는 있지만, 한국 문화의 맥락과 서사를 충분히 이해하지 못하고 있다"고 지적했다. 그는 문화 데이터가 단순한 사실 정보를 넘어 맥락, 서사, 전문가 고증을 포함하는 '설명 가능한 데이터'로 구축돼야 한다고 강조했다. 또한 보도자료, 민속문화대백과 등 현재 추진 중인 AI 학습용 문화 데이터 구축 사례를 소개하며 고해상도 원천 데이터, 정교한 메타 데이터, 다국어 번역 검증의 중요성을 역설했다. 이 팀장은 "민간이 할 수 없는 기본 인프라와 신뢰 가능한 기준을 공공이 먼저 만들어야 한다"며 공공 부문의 역할을 강조했다.
이은진 게임물관리위원회 이사 겸 명지전문대학 AI게임소프트웨어학과 교수는 '유럽 사례에 나타난 문화 데이터 공유 논의의 핵심 쟁점'을 통해 문화 경쟁의 무대가 콘텐츠 생산에서 데이터 학습 질서로 이동하고 있음을 짚었다. 이 교수는 "문화는 더 이상 결과물이 아니라 학습 데이터가 되었으며, AI 시대의 문화 주권은 ‘얼마나 퍼뜨렸는가’가 아니라 어떤 기준과 구조로 학습되었는가에 달려 있다"고 강조했다.
특히 유럽의 Gaia-X와 데이터스페이스 논의가 문화 데이터 확산 과정에서 출처, 책임, 권리, 분쟁 처리 기준이 붕괴되는 문제에 대한 제도적 대응 사례로 분석했다. 이 교수는 유럽의 접근 방식이 특정 제도를 모방하는 데 있기보다, 데이터 공유를 둘러싼 질서와 신뢰 구조를 어떻게 설계했는지를 주목할 필요가 있다고 설명했다.
그는 유럽이 문화데이터를 한 곳에 집중시키는 대신, 각 주체가 데이터를 보유한 상태에서 공통 규칙과 신뢰, 책임 구조를 먼저 합의하고 이를 시스템으로 구현해 왔다고 설명했다. 이러한 접근이 데이터 공유를 기술이나 플랫폼의 문제가 아니라, 질서와 거버넌스의 문제로 다루고 있다는 점에서 주목할 필요가 있다고 덧붙였다. 이 교수는 "한국 역시 문화 데이터 공유를 단순한 활용이나 개방의 문제가 아니라, 문화 주권과 인지 주권을 지키기 위한 질서 설계의 관점에서 접근할 필요가 있다"라고 밝혔다.
마지막 발제자인 신철호 연세대학교 정치외교학과 겸임교수 겸 OGQ 대표는 'AI 윤리와 편향: 문화 데이터 거버넌스를 위한 기준과 방향'을 주제로 발표했다. 이를 통해 AI 편향 문제가 기술적 오류가 아니라 학습 데이터 구조와 규칙 설계의 문제라고 지적했다. 이미지 및 언어 생성 AI에서 반복적으로 나타나는 인종, 성별, 문화, 직업, 라이프스타일의 편향 사례를 분석하며 "AI의 ‘중립성’은 실제로는 서구 중심 데이터와 안전 규칙이 결합된 결과"라고 설명했다.
또한 저작권이 불분명한 데이터 학습이 창작자 권리 침해와 K-콘텐츠 신뢰도 하락으로 이어질 수 있다고 경고하며, AI 학습 단계부터 윤리, 저작권, 편향을 검증하는 필터링 체계와 국가 차원의 신뢰 가능한 AI 윤리 데이터셋 구축 필요성을 강조했다.
종합 토론에서는 문화 데이터 공유가 단순한 데이터 개방이나 활용 촉진 문제를 넘어, 접근 권한과 사용 조건, 결과에 대한 책임 주체를 명확히 하는 거버넌스 설계 문제라는 공통 인식이 확인됐다.
참석자들은 AI 시대 K-컬처 경쟁력이 콘텐츠 생산량보다 학습 구조와 신뢰 체계를 선점하는 능력에 달려 있으며, 이를 위해 공공, 민간, 학계가 함께 참여하는 문화 데이터 공유체계 구축이 필요하다는 데 의견을 모았다.



























 리그 오브 레전드
리그 오브 레전드
.jpg) 메이플스토리
메이플스토리
 리니지
리니지
 FC 온라인
FC 온라인
 플레이어언노운스 배틀그라운드
플레이어언노운스 배틀그라운드
 발로란트
발로란트
 메이플스토리 월드
메이플스토리 월드
 오버워치(오버워치 2)
오버워치(오버워치 2)
 서든어택
서든어택
 아이온2
아이온2